
Basic Statistics (Part 1)#
Prerequisite:
None
We will learn:
Random variable (RV), how to generate random numbers in \(\texttt{python}\)
Probability distribution function (PDF)
Histograms
Basic statistics (mean, median, standard deviation)
We will use them to understand
Detectors and astronomical images
Calibration frames: bias, flat field, dark
A good reference: A Beginner Guide to Astro-Statistics and Astro-Machine-Learning, by Yuan-Sen Ting
# Let's start with importing our packages
import numpy as np
import scipy
import matplotlib
import matplotlib.pyplot as plt
# We can beautify our plots by changing the matpltlib setting a little
plt.rcParams['font.size'] = 18
plt.rcParams['axes.linewidth'] = 2
1. Random variable, histogram, probability#
Let’s look at a cubic die with faces numbered from 1 to 6. When you roll a die once, you write down the number on the top (e.g., 4). Then when you roll it again, you might see a different number (e.g., 2). You can repeat this many times, and you will probably see all six numbers. An event such as a die roll is called a random event. The outcome of a die roll is a random variable. Let’s denote the random variable of a die roll as \(X\), so the value of \(X\) must be in \(\{1, 2, 3, 4, 5, 6\}\). One must realize that a random variable is a variable – it can have different values \(x\) when repeating the random event.
Let’s use Python to generate random numbers to get a sense of rolling a “fair” die. np.random.randint (or scipy.stats.randint) provides a nice function to generate a random variable that is an integer between 1 and 6.
# run this cell many times, as if you are rolling a die
print(np.random.randint(low=1, high=6+1)) # notice that `high` is one plus the highest number of our random variable. This trick is common in python.
2
Now you see what a random variable looks like. Shall we roll a die for 100 times and record all the outcomes?
N_roll = 100
outcomes = []
for i in range(N_roll): # do the following operation for 100 times
outcomes.append(np.random.randint(low=1, high=6+1))
outcomes = np.array(outcomes)
outcomes
array([2, 3, 1, 4, 4, 4, 2, 3, 3, 3, 4, 1, 5, 4, 4, 2, 2, 5, 4, 1, 6, 6,
4, 1, 4, 2, 6, 2, 6, 3, 1, 6, 1, 5, 5, 5, 3, 3, 1, 6, 6, 2, 1, 3,
3, 6, 1, 2, 3, 1, 2, 6, 4, 3, 1, 4, 2, 5, 4, 1, 5, 1, 5, 5, 5, 4,
5, 6, 2, 6, 6, 4, 5, 2, 5, 6, 3, 3, 2, 6, 1, 3, 6, 5, 5, 5, 6, 5,
4, 1, 5, 4, 5, 4, 1, 4, 1, 1, 2, 3])
Here we use a list outcomes to store the outcome from each roll. The for loop is used to repeat the die roll for N_roll times. It is a good practice to define variables like N_roll in your code, because if you want to change the number of dice rolls to 10000, you can just change N_roll = 10000 without touching other code. The benefit of this practice will manifest itself as we go on in this course. Also, it is usually more convenient to work with numpy arrays than python lists.
Our next task is to check the frequency of the outcome being each number between 1 and 6.
np.sum(outcomes == 1) # this shows the frequency of "1" in the 100 rolls
18
np.sum(outcomes == 4) # this shows the frequency of "4" in the 100 rolls
18
# Let's use the for loop again
for i in range(1, 6+1):
print(f'The frequency of {i} is', np.sum(outcomes == i))
The frequency of 1 is 18
The frequency of 2 is 14
The frequency of 3 is 15
The frequency of 4 is 18
The frequency of 5 is 19
The frequency of 6 is 16
Again, numpy provides shortcut functions to do this:
values, counts = np.unique(outcomes, return_counts=True)
print(values, counts)
print(list(zip(values, counts)))
[1 2 3 4 5 6] [18 14 15 18 19 16]
[(1, 18), (2, 14), (3, 15), (4, 18), (5, 19), (6, 16)]
Histogram is a good tool to visualize this result
plt.hist(outcomes, bins=np.arange(1, 6+2) - 0.5, histtype='bar', rwidth=0.4)
plt.xlabel('Outcome')
plt.ylabel('Frequency')
plt.title(f'Number of rolls: {N_roll}');
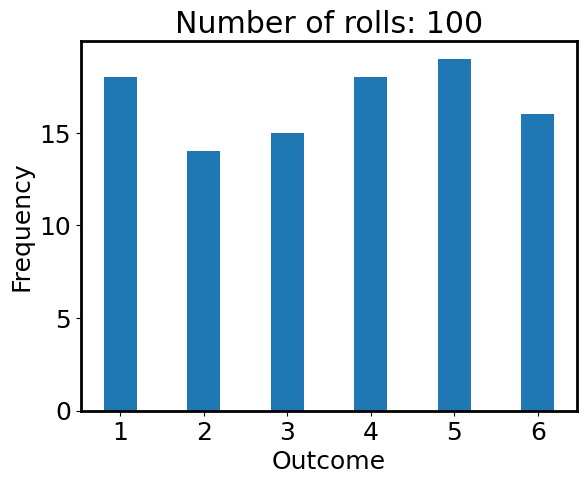
Is the die fair? Seems no from the figure above, because the frequencies of all numbers are not the same. This contradicts our assumption of using np.random.randint where the outcomes should be random. What’s happening here? Let’s calculate the chance of the outcome being each number:
chances = counts / N_roll
print(chances)
[0.18 0.14 0.15 0.18 0.19 0.16]
If the die is fair, the chances should all be 1/6 = 0.1667. We see that the chances are not exactly 0.1667, but quite close. In math, this “chance” is called “probability”.
Exercise 1#
Let’s increase N_roll to 10000, repeat the above exercise again and plot the histogram. In plt.hist function, you can turn on density=True to plot the “normalized frequency” (each frequency divided by the sum of all frequencies, i.e., total number of rolls). The normalized frequencies should be very close to the probability 1/6 (red dashed line).
The purpose is to acknowledge an important thing: the conclusion is subject to statistical uncertainty when the sample size is too small.
2. Mean, Median, Standard Deviation#
These are the most useful statistics and are of great importance in astronomical data. If we have a set of data \(\{x_1, x_2, \dots, x_{n}\}\), these statistics are defined to be:
Mean: \(\overline{x} = \dfrac{1}{n}(x_1 + x_2 + \cdots + x_n)\)
Median: “the middle number”. This is found by ordering all data and picking out the one in the middle (or if there are two middle numbers, taking the mean of those two numbers)
Standard deviation: it measures how disperse the data is \(\sigma = \sqrt{\dfrac{(x_i - \overline{x})^2}{n}}\).
Variance: it is typically the square of standard deviation, \(\sigma^2\).
(maybe add a footnote to discuss the unbias estimator for sample variance, i.e., N-1 v.s. N)
Let’s generate some data by sampling from a uniform distribution from 0 to 1, and calculate their mean, median, and standard deviation.
# sample from a uniform distribution U(0, 1)
n_sample = 200 # sample size
data = np.random.uniform(0, 1, size=(n_sample,))
# Take a look at the data
print(data[:10])
[0.04155899 0.08288533 0.76149162 0.63469864 0.26931678 0.38631496
0.74957029 0.24235966 0.87746144 0.91011673]
Indeed, they are decimals between 0 and 1. Is there a way to visualize their distribution? Yes, we just learned about histogram:
plt.hist(data, bins=5); # indeed, it looks like a uniform distribution
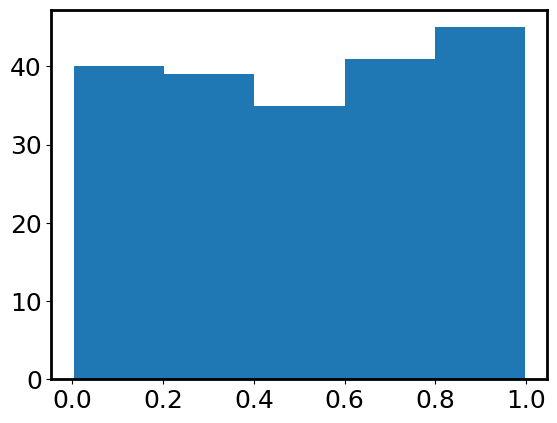
numpy provides some handy functions to do basic statistics.
np.mean(data), np.median(data), np.std(data)
(0.5067891891521236, 0.5282826270333825, 0.2913335882457618)
To verify that np.std does return the standard deviation, we calculate it manually following \(\sigma = \sqrt{(x_i - \overline{x})^2/ n}\).
np.sqrt(np.sum((data - np.mean(data))**2 / len(data)))
# Okay, `np.std` does its job pretty well.
0.2913335882457618
From Wikipedia (you can also calculate by yourselves), the mean, median, and standard deviation of a uniform distribution \(U[a, b]\) are \((a+b)/2\), \((a+b)/2\), and \(\sqrt{3} (b-a)/ 6\). Do our numerical results agree with these analytical expressions?
Outlier#
An additional data point with a value of 100 (aka outlier) was added to the above data set unknowingly.
data = np.concatenate([data, [100]])
Let’s still calculate mean, median, and standard deviation.
np.mean(data), np.median(data), np.std(data)
(1.0017802877135558, 0.5344399432394888, 7.0062608091390315)
Oooops! The mean and standard deviation are completely off, but the median remains similar to what we had above. An outlier, being unusually small or unusually large, can greatly affect the mean but not affect the median much! Consider using median if you worry about outliers! We will illustrate this point more when we play with the calibration files.
3. Gaussian (normal) distribution#
The normal distribution is the most important distribution in statistics. The probability distribution function (PDF) has a beautiful form of \(p(x) = \frac{1}{\sqrt{2\pi} \sigma} e^{-\frac{(x-\mu)^2}{2\sigma^2}},\) where \(e=2.71828..\) is the base of natural logarithms, and \(\mu\) and \(\sigma\) control the centroid and the width (dispersion) of the distribution, respectively. A normal distribution is often written as \(\mathcal{N}(\mu, \sigma^2)\). Its PDF has a bell-like shape.
For a random variable following a normal distribution, its mean is \(\mu\) and its standard deviation is \(\sigma\). Let’s check it by sampling from a standard normal distribution, whose \(\mu=0\) and \(\sigma=1\).
n_sample = 10000 # sample size
mu, sigma = 0, 1 # standard normal distribution
data = np.random.normal(loc=mu, scale=sigma, size=(n_sample))
data.shape
(10000,)
np.mean(data), np.median(data), np.std(data)
# Indeed, the mean and median of this data is very close to 0.
# The standard deviation is very close to 1.
(-0.004258352989279034, -0.010502977849982373, 1.0089792198475847)
# Let's visualize it
plt.hist(data, bins=30);
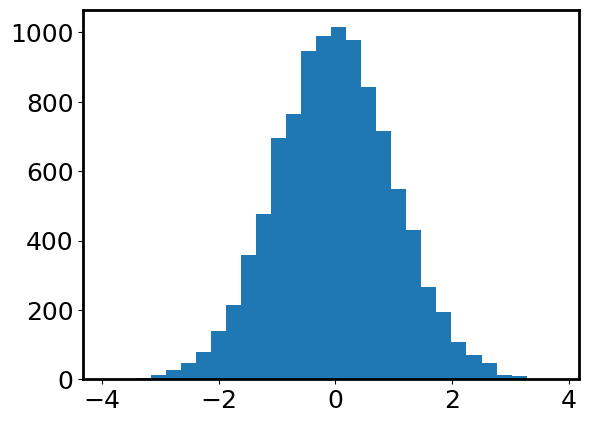
From this histogram, we indeed see that the distribution is centered at 0 and has a bell-like shape. More importantly, we see that most data points fall within \([-3, 3]\). Let’s try to count how many data points are outside of \([-3, 3]\). This is equivalent to asking how many data points are \(>3\) away from the mean \(\mu=0\).
np.sum(np.abs(data) > 3)
31
fraction = np.sum(np.abs(data) > 3) / len(data)
print(f'Only {fraction * 100}% of the data points are outside of [-3, 3].')
Only 0.16999999999999998% of the data points are outside of [-3, 3].
More generally speaking, for a random variable following a normal distribution \(\mathcal{N}(\mu, \sigma^2)\), the chance of being \(3\sigma\) away from the mean value \(\mu\) is very very slim (rigorously speaking, \(P(|x-\mu|>3\sigma) = 0.0027\)).
This leads us to the “68–95–99.7 rule”, which describes the fact that, for a normal distribution, the percentage of values that lie within \(1\sigma\), \(2\sigma\), and \(3\sigma\) from the mean is 68%, 95%, and 99.7%.
It is useful to remember these three numbers.
Exercise 2#
Let’s sample a standard normal distribution by doing
Xs = np.random.normal(0, 1, n_sample), wheren_sample = 1000.Define a new random variable
Ys = Xs + 3. What’s the mean and the standard deviation of this random variableYs? You can also try to validate your answer usingnp.meanandnp.std.Define a new random variable
Zs = 2 * Xs - 3. What’s the mean and the standard deviation of this random variableZs?(Optional) Extra credit: \(X\) and \(Y\) are two independent random variables following a standard normal distribution. What’s the distribution of \(X+Y\)?
4. Poisson distribution and its relation to Gaussian#
Named after the French mathematician Siméon Denis Poisson (Poisson in French means fish 🐟), a Poisson distribution describes the probability of a given number of events occurring in a fixed interval of time if these events occur with a known constant mean rate. Because now the probability is a function the “number” of events, the Poisson distribution is a discrete distribution – the values sampled from a Poisson distribution are all positive integers.
The PDF of a Poisson distribution is \( P(X=k) = \dfrac{\lambda^k e^{-\lambda}}{k!}, \) where \(\lambda\) is the mean event rate, and \(!\) is factorial.
In astronomy, the number of photon that we receive in a certain period of time (say during a 1000s exposure) follows a Poisson distribution. The mean rate of photons from a star is a known constant (it’s related to the so-called flux). In the following, let’s explore the Poisson distribution by studying the number of observed photons.
# Assume the average number of photon from a star is 10 during a 900s exposure
photon_rate = 4
# We "observe" this star for 500 times.
# Each time we can count how many photons we get, denoted by $x$.
# This is equivalent to sampling from a Poisson distribution with $\lambda = 4$
n_exposure = 1000
photon_counts = np.random.poisson(photon_rate, size=(n_exposure,))
photon_counts[:30]
array([3, 0, 4, 5, 3, 5, 2, 3, 5, 7, 4, 4, 2, 3, 4, 8, 4, 2, 3, 6, 9, 1,
2, 4, 3, 7, 6, 4, 3, 7])
This means we get different numbers of photons in different exposures. How are they distributed?
plt.hist(photon_counts, range=(0, 10));
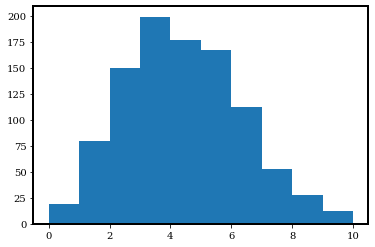
We have several observations from the above figure:
The distribution does not extend to the negative half of the x-axis. This is because Poisson distribution is only defined for \(x>=0\).
It does not look like a bell. Instead, the shape is not quite axisymmetric. We call it “skewed”.
It seems like the number of photons covers a wide range, but is centered around
photon_rate=4. Let’s calculate the mean, median, and variance.
np.mean(photon_counts), np.median(photon_counts), np.var(photon_counts)
(3.892, 4.0, 3.9283360000000003)
It is striking that the mean, and variance are all very close to the \(\lambda=\) photon_rate \(=4\). Actually, for a Poisson distribution, its mean and variance are indeed \(\lambda\). So the standard deviation is \(\sqrt{\lambda}\). That means a Poission distribution with a larger \(\lambda\) is also “wider” or “more dispersed”.
Now let’s move to the bright side: assume the photon rate is very large, photon_rate=2000. And we take 10000 exposures.
photon_rate = 2000
n_exposure = 10000
photon_counts = np.random.poisson(photon_rate, size=(n_exposure,))
plt.hist(photon_counts, bins=30, histtype='step');
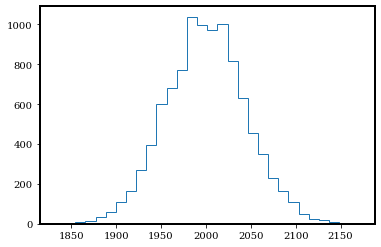
np.mean(photon_counts), np.median(photon_counts), np.var(photon_counts)
(1999.7938, 2000.0, 1997.2740815599996)
Now this Poisson distribution looks a lot more similar to a Gaussian distribution. Let’s sample a Gaussian distribution with the same mean (photon_rate) and standard deviation (np.sqrt(photon_rate)) as this Poisson distribution, and compare.
gaussian_data = np.random.normal(photon_rate, np.sqrt(photon_rate), size=(n_exposure,))
plt.hist(photon_counts, bins=30, histtype='step', label='Poisson');
plt.hist(gaussian_data, bins=30, histtype='step', label='Gaussian');
plt.legend();
<matplotlib.legend.Legend at 0x7fd599e0b6d0>
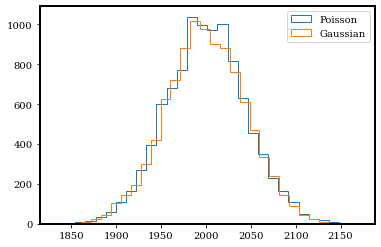
Yes! They do look very very similar now. For large \(\lambda\), a normal distribution is an excellent approximation to a Poisson distribution.
5. Example: A noisy image#
Most astronomical data are in the form of image. An image is typically a two-dimentional array. In this section, we will try to simulate an image of a flat object which emits photon at a constant rate (photon_rate=4). We will also understand how to possibly reduce the noise in images.
plt.rcParams['figure.figsize'] = (8, 8)
As we introduced above, each pixel of the image should follow a Poisson distribution with \(\lambda=4\).
# Let's define an image size, e.g., 200 x 200
img_size = 200
photon_rate = 4
img = np.random.poisson(photon_rate, size=(img_size, img_size))
plt.imshow(img, cmap='binary');

This looks like the “snow screen” when an old TV has no connection! It is indeed what a noisy image look like!
It would be interesting to calculate the mean and variance of this noisy image. The function np.mean and np.var supports high-dimensional data inputs, and you can even calculate the mean or std along a specific axis.
np.mean(img), np.var(img) # nice Poisson distribution
(3.995075, 4.011300744375)
# This calculate the mean for each column of the noisy image
np.mean(img, axis=0)
array([4.19 , 3.96 , 4.075, 4.12 , 3.815, 4.235, 4.165, 4.085, 3.695,
4.115, 4.005, 3.74 , 3.95 , 4.06 , 4.2 , 4.03 , 3.955, 3.8 ,
4.26 , 3.695, 4.16 , 3.825, 3.925, 4.13 , 4.09 , 4. , 3.925,
3.96 , 3.92 , 4.135, 3.885, 3.975, 4.075, 4.07 , 3.96 , 4.08 ,
3.97 , 3.88 , 4.045, 3.665, 4.215, 3.865, 3.955, 4.025, 4.11 ,
4.14 , 4.025, 4.005, 3.955, 4.045, 4.16 , 3.995, 3.7 , 3.805,
3.735, 4.125, 3.735, 4.275, 4.025, 4. , 4.015, 3.945, 3.81 ,
4.105, 3.945, 4.12 , 4.06 , 4.065, 4.22 , 4.03 , 4.14 , 4.135,
3.85 , 4.14 , 4.15 , 4.12 , 3.84 , 3.955, 4.09 , 4.21 , 3.925,
4.26 , 4.08 , 3.74 , 4.015, 3.87 , 3.86 , 4.075, 3.85 , 3.89 ,
3.93 , 3.775, 3.94 , 3.92 , 4.045, 3.76 , 4.01 , 4.1 , 4.135,
3.895, 3.785, 4.075, 3.85 , 3.95 , 4.08 , 4.165, 4.01 , 3.74 ,
3.895, 4.215, 4.04 , 3.935, 4.015, 4.01 , 3.845, 3.92 , 3.795,
4.01 , 3.98 , 3.89 , 4.005, 3.8 , 4.03 , 3.65 , 3.87 , 4.055,
4.055, 3.835, 3.955, 4.055, 3.91 , 4.045, 4.095, 3.775, 4.065,
3.88 , 4.105, 3.825, 3.94 , 3.945, 4.03 , 4.05 , 3.825, 4.175,
3.775, 4.245, 3.94 , 4.15 , 3.945, 4.16 , 4.04 , 4.065, 3.985,
3.875, 4.14 , 4.03 , 4.04 , 4.015, 4.085, 4.055, 3.935, 4.195,
4.11 , 3.845, 4.395, 3.865, 4.085, 3.965, 3.87 , 4.08 , 4.025,
3.72 , 4.015, 3.935, 3.945, 4.01 , 3.955, 4.12 , 3.895, 3.965,
4.13 , 3.96 , 4.16 , 3.94 , 4.05 , 4.155, 3.935, 4.225, 4.06 ,
4.02 , 3.925, 3.935, 3.995, 3.915, 3.87 , 3.79 , 4.27 , 4.22 ,
4.135, 3.93 ])
# We can also plot the histogram for the pixel values.
# You need to "flatten" the 2-D image to a 1-D array
plt.hist(img.flatten(), bins=30, histtype='step'); # looks like Poisson
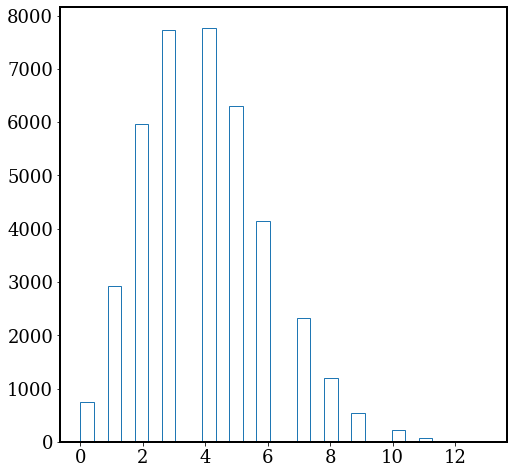
We discuss the concept “signal-to-noise ratio” (S/N, or SNR) here. The signal we want to receive from this image is \(\lambda=4\), which is the average photon rate from the object. However, the image is quite noisy. The standard deviation of pixel values is a proxy for how noisy the image is. Therefore, the SNR of this image is:
SNR = np.mean(img) / np.std(img)
print(SNR)
1.994721757261882
In fact, for a Poisson distribution with \(\lambda=4\), mean=4, std=2, so the SNR should just be 2.
SNR=2 is too low for any science. But you might have heard that stacking images will reduce the noise. Why not try taking 16 exposures and combining them together?
img_size = 200
photon_rate = 4
img_list = []
for i in range(16):
img = np.random.poisson(photon_rate, size=(img_size, img_size))
img_list.append(img)
img_list = np.array(img_list)
img_list.shape
(16, 200, 200)
Remember that each pixel follows a Poisson distribution with \(\lambda=4\). For a pixel at a given location, it now has 16 different values from 16 exposures. We can calculate the mean or median of these values as a way to “combine” these exposure. This can be done using np.mean(img_list, axis=0) or np.median(img_list, axis=0). axis=0 means we are averaging along the first axis of img_list, i.e., averaging over different exposures.
After combining these exposures, we show the combined image using the same scale as the one above.
img_avg = np.mean(img_list, axis=0)
plt.imshow(img_avg, cmap='binary', vmin=0, vmax=12);

The combined image is much smoother than a single exposure image! If you increase the number of exposures, the combined image will even smoother. Another way to look at this is to plot the histogram of pixel values:
Exercise 3#
Plot the histograms of pixel values in a single image
imgand the combined imageimg_avg. (Tips: you can’t simply doplt.hist(img). You have to first flatten the 2D array byimg.flatten(), then useplt.histfunction). Which histogram is narrower?Calculate the SNRs for a single image and the combined image.
How much do we boost the SNR by combining 16 single exposures?
Now we realize that an effective way to fight down noise is to combine lots of exposures. More generally, SNR is proportional to \(\sqrt{N}\) where \(N\) is the number of exposures combined.
## Your answer here
Exercise 4#
Let’s revisit the football data from last week in order to practice calculating the mean, median, and mode of some distributions.
Show code cell source
# Don't worry about this cell, it's just to make the notebook look a little nicer.
try:
import google.colab
IN_COLAB = True
except ImportError:
IN_COLAB = False
# Get the directory right
if IN_COLAB:
from google.colab import drive
drive.mount('/content/drive/')
os.chdir('/content/drive/Shareddrives/AST207/data')
else:
os.chdir('../../../_static/ObsAstroData/')
# Read the catalog of the football players
cat = Table.read('./players_age.csv')
Calculate the mean, median, and mode of the player height (in inches).
## Your answer goes here
Are the three numbers different? If so, why? If not, why not?
## Your answer goes here
Make a histogram of the player height in the same units. Do your answers make sense?
## Your answer goes here
Calculate the mean, median, and mode of the player age. Again histogram the player age and determine if your answers make sense.
## Your answer goes here
Extra credit: find height and age data for typical people in the United States and compare our statistics with those of football players. How can you compare the distributions?
## Your answer goes here